Craigslist Listcrawler: Unlocking the potential of Craigslist data requires understanding the intricacies of listcrawlers. This guide delves into the functionality, legal aspects, technical development, data handling, applications, and security considerations surrounding these powerful tools. We’ll explore how to responsibly extract valuable information from Craigslist while navigating its terms of service and ethical implications.
From the core mechanics of data extraction to advanced techniques for bypassing anti-scraping measures, we’ll cover the entire lifecycle of building and utilizing a Craigslist listcrawler. We’ll examine the diverse applications across various industries, highlighting both the benefits and potential pitfalls. This comprehensive exploration aims to empower you with the knowledge and best practices for responsible and effective Craigslist data harvesting.
Craigslist Listcrawler Functionality
A Craigslist listcrawler is a program designed to automatically extract data from Craigslist postings. This involves systematically navigating Craigslist’s website, identifying relevant postings, and extracting specific pieces of information. Understanding its core mechanics, data extraction capabilities, and legitimate applications is crucial for responsible use.
Core Mechanics of a Craigslist Listcrawler
A Craigslist listcrawler typically uses web scraping techniques to access and parse Craigslist’s HTML source code. It starts by defining search criteria (e.g., location, s, category), then iterates through search results pages, following links to individual postings. For each posting, it extracts data based on predefined rules or patterns, often using regular expressions or other pattern-matching techniques. The extracted data is then cleaned, organized, and stored for later analysis or use.
Types of Data Extracted from Craigslist Postings
Craigslist listcrawlers can extract a wide variety of data, depending on the specific needs of the user. This can include, but is not limited to: title, description, price, location, date posted, images (URLs), contact information (if available and permissible), and any other relevant details present in the posting’s HTML.
Legitimate Uses of a Craigslist Listcrawler
While often associated with potentially problematic activities, Craigslist listcrawlers have legitimate uses. Researchers might use them to study pricing trends in specific markets, real estate professionals could track property listings, and job seekers could monitor employment opportunities. Market analysis firms may use them to gather data for competitor analysis.
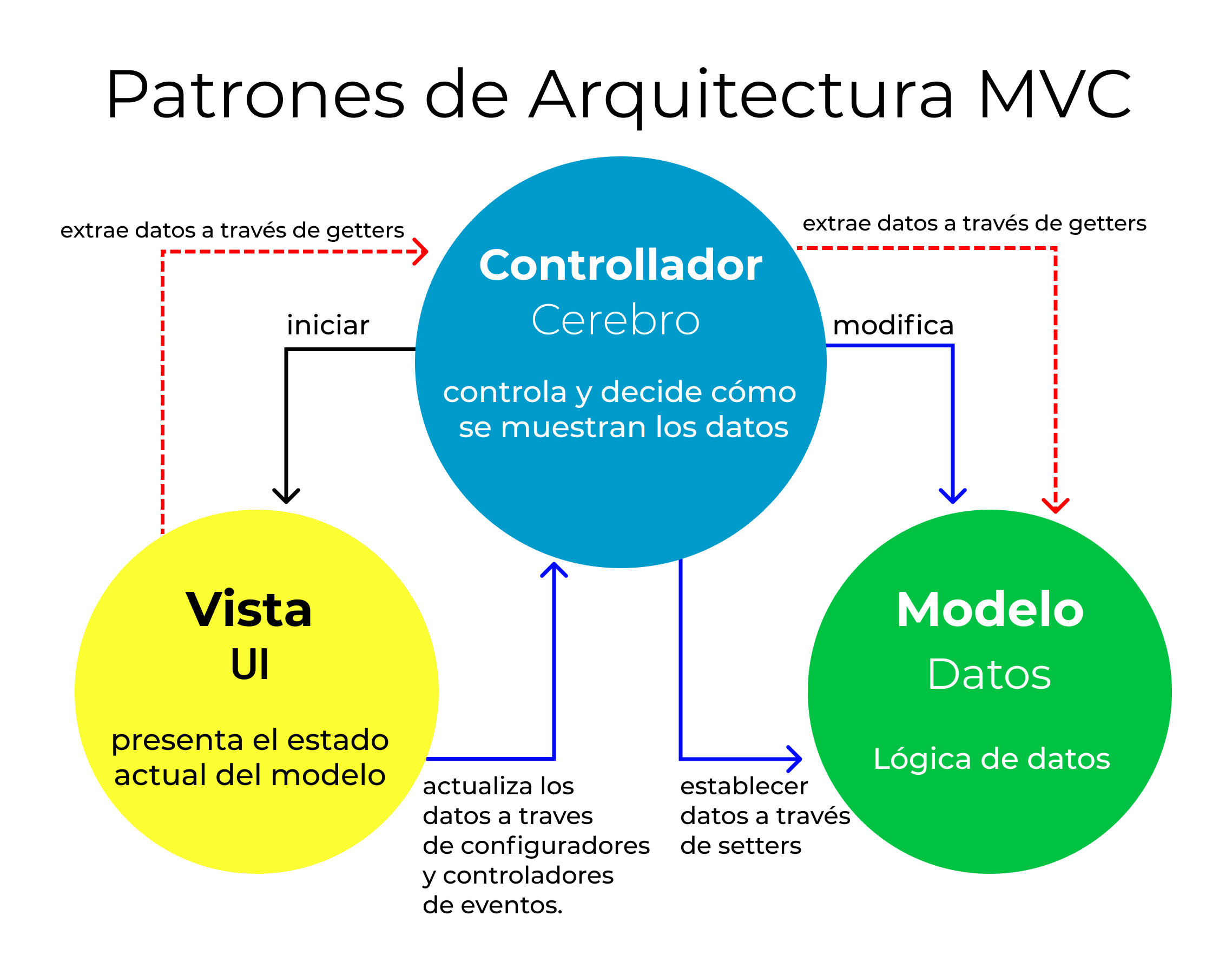
Flowchart for Building a Basic Craigslist Listcrawler
The process of building a basic Craigslist listcrawler can be visualized through a flowchart. The flowchart would begin with defining search parameters, then proceed to web scraping, data extraction, data cleaning, and finally, data storage. Error handling and rate limiting would be integrated throughout the process to ensure robustness and compliance with Craigslist’s terms of service. A visual representation would show the sequential steps and decision points involved, such as handling exceptions during scraping and implementing delays to avoid overloading the server.
Legal and Ethical Considerations
Using a Craigslist listcrawler carries significant legal and ethical implications. Understanding and adhering to Craigslist’s terms of service, respecting user privacy, and employing responsible data collection practices are paramount.
Legal Implications of Using a Craigslist Listcrawler
Craigslist’s terms of service explicitly prohibit automated scraping. Violating these terms can lead to account suspension or legal action. The legality of web scraping varies by jurisdiction and depends on factors such as the method used, the amount of data collected, and the purpose of collection. Always consult legal counsel before undertaking large-scale scraping projects.
Ethical Concerns Related to Data Privacy
Extracting personal information from Craigslist postings raises serious ethical concerns. Respecting user privacy is critical. Avoid collecting or storing personally identifiable information (PII) unless absolutely necessary and with explicit consent. Anonymization and aggregation techniques should be employed to protect user privacy.
Best Practices for Responsible Data Collection
Responsible data collection involves respecting Craigslist’s terms of service, implementing rate limiting to avoid overloading their servers, and avoiding the collection of PII. Always use a robots.txt checker to ensure compliance with website directives. Transparency is also crucial; if the data is used for research or analysis, clearly state the source and methodology.
Legal Implications of Different Scraping Techniques
| Technique | Legality | Ethical Concerns | Best Practices |
|---|---|---|---|
| Simple HTTP requests | Potentially legal, depending on terms of service | Minimal, if data is anonymized | Respect robots.txt, implement rate limiting |
| Advanced techniques (e.g., headless browsers) | More likely to violate terms of service | Higher, due to potential for increased data collection | Strictly adhere to robots.txt, implement robust rate limiting, anonymize data |
| API usage (if available) | Generally legal and ethical | Minimal, as data access is authorized | Follow API usage guidelines |
| Data aggregation from multiple sources | Legality depends on individual sources’ terms of service | Depends on individual sources’ privacy policies | Ensure compliance with each source’s terms of service and privacy policies |
Technical Aspects of Development: Craigslist Listcrawler
Building a Craigslist listcrawler requires familiarity with programming languages, web scraping libraries, and techniques for handling website structure and anti-scraping measures.
Programming Languages and Libraries
Python is a popular choice for web scraping due to its extensive libraries like Beautiful Soup and Scrapy. Other languages such as Node.js with libraries like Cheerio can also be used. The choice of language and library often depends on developer preference and project requirements. Scrapy, for instance, provides a robust framework for building efficient and scalable crawlers.
Performance of Web Scraping Libraries
The performance of different web scraping libraries varies depending on factors such as the complexity of the target website, the amount of data being extracted, and the efficiency of the library’s parsing algorithms. Benchmarking is essential to determine the optimal library for a given task. Factors like speed, memory usage, and ease of use should be considered when selecting a library.
Challenges in Handling Craigslist’s Website Structure
Craigslist’s website structure can be dynamic and complex, making it challenging to write robust scraping scripts. Regular expressions may need to be carefully crafted to handle variations in HTML structure. The site also frequently updates its structure, requiring regular maintenance and updates to the scraping scripts.
Craigslist listcrawler tools are useful for efficiently scanning numerous listings, but their applications extend beyond simple property searches. For instance, one might use such a tool to track down mentions of, say, celebrities slips in online classifieds, though the relevance of such data would be questionable. Ultimately, the effectiveness of a Craigslist listcrawler depends entirely on the user’s specific needs and how they utilize the gathered information.
Implementing Error Handling and Rate Limiting
A robust Craigslist listcrawler incorporates error handling to gracefully manage unexpected situations, such as network errors or changes in the website’s structure. Rate limiting is essential to avoid overloading Craigslist’s servers and potentially getting blocked. This typically involves introducing delays between requests, using proxies, and rotating user agents.
- Implement
try-exceptblocks to catch and handle potential exceptions (e.g., network errors, HTTP errors). - Use libraries or modules to manage delays between requests (e.g.,
time.sleep()in Python). - Consider using proxies to distribute requests across different IP addresses.
- Rotate user agents to mimic different browsers and avoid detection.
Data Processing and Analysis
Once data is extracted, it needs to be cleaned, organized, and prepared for storage and potential analysis. This involves handling inconsistencies, removing duplicates, and structuring data for efficient use.
Cleaning and Organizing Extracted Data
Data cleaning involves handling inconsistencies in formatting, removing irrelevant characters (e.g., HTML tags), and standardizing data types. This might involve using regular expressions to clean text, converting data types, and handling missing values. The goal is to create a consistent and usable dataset.
Structuring Data for Efficient Storage and Retrieval, Craigslist listcrawler
Efficient storage and retrieval usually involves storing the data in a structured format like a database (e.g., SQL, NoSQL). Choosing the right database depends on the size and type of data and the intended use. Relational databases are suitable for structured data, while NoSQL databases are better for unstructured or semi-structured data.
Identifying and Removing Duplicate or Irrelevant Data
Duplicate data can be identified using various techniques such as hashing or comparing key fields. Irrelevant data can be removed based on predefined criteria or through manual review. This step ensures the data used for analysis is accurate and reliable.
Data Visualization Techniques
- Histograms for price distributions
- Scatter plots for comparing price and location
- Bar charts for visualizing the frequency of specific s
- Geographic maps for visualizing location data
Applications and Use Cases
Craigslist listcrawlers find application across various industries, aiding in market research, price comparison, and the development of specialized applications.
Real-World Examples of Craigslist Listcrawler Use
Real estate companies might use listcrawlers to monitor property listings for specific criteria. Used car dealerships might track vehicle listings to assess market pricing. Researchers could use them to study the dynamics of various markets by analyzing price fluctuations and other relevant factors.
Assisting in Market Research
A listcrawler can gather data on product pricing, availability, and demand across different regions, allowing businesses to gain valuable insights into market trends without manual data entry. This information can inform strategic decisions related to pricing, inventory management, and market expansion.
Price Comparison Across Different Craigslist Regions
A listcrawler can automate the process of comparing prices for the same product across different Craigslist regions. By collecting price data from multiple locations, businesses can identify regional price variations and optimize their pricing strategies accordingly. This can be particularly useful for businesses with a wide geographic reach.
Hypothetical Application Using Craigslist Data
Imagine an application that aggregates and displays Craigslist listings for rental properties, allowing users to filter results by price, location, amenities, and other criteria. The application could provide interactive maps, price comparison tools, and alerts for new listings matching user preferences. The application could also analyze trends in rental prices over time.
Security and Anti-Scraping Measures
Craigslist employs various anti-scraping techniques, and using a listcrawler carries security risks. Understanding these techniques and implementing appropriate security measures are crucial for responsible and safe use.
Common Anti-Scraping Techniques
Craigslist may use techniques such as IP blocking, CAPTCHAs, rate limiting, and sophisticated bot detection mechanisms to prevent automated scraping. These techniques are designed to protect their servers from overload and prevent unauthorized data access.
Methods for Bypassing or Mitigating Anti-Scraping Techniques
Methods for responsibly mitigating anti-scraping techniques include using proxies to rotate IP addresses, implementing delays between requests, and using headless browsers to mimic human browsing behavior. However, it’s crucial to respect Craigslist’s terms of service and avoid aggressive techniques that could overwhelm their systems.
Security Risks Associated with Using a Listcrawler
Security risks include data breaches if the crawler is not properly secured, unauthorized access to sensitive data, and potential legal repercussions for violating Craigslist’s terms of service. Improperly configured crawlers could expose personal information or become targets for malicious attacks.
Security Best Practices
- Use secure coding practices to prevent vulnerabilities.
- Implement robust error handling to prevent crashes and data loss.
- Store sensitive data securely, using encryption and access controls.
- Regularly update libraries and software to patch security vulnerabilities.
- Respect robots.txt and Craigslist’s terms of service.
Summary
Source: hexomatic.com
Building and utilizing a Craigslist listcrawler presents a unique opportunity to access and leverage a vast amount of data. However, responsible development and deployment are paramount. By understanding the legal and ethical considerations, mastering the technical challenges, and prioritizing data security, you can harness the power of Craigslist data for legitimate purposes while upholding ethical standards and adhering to Craigslist’s terms of service.
This guide provides a framework for responsible data collection and analysis, empowering you to navigate the complexities of this powerful tool effectively.